
Adapting Language-Audio Models as Few-Shot Audio Learners
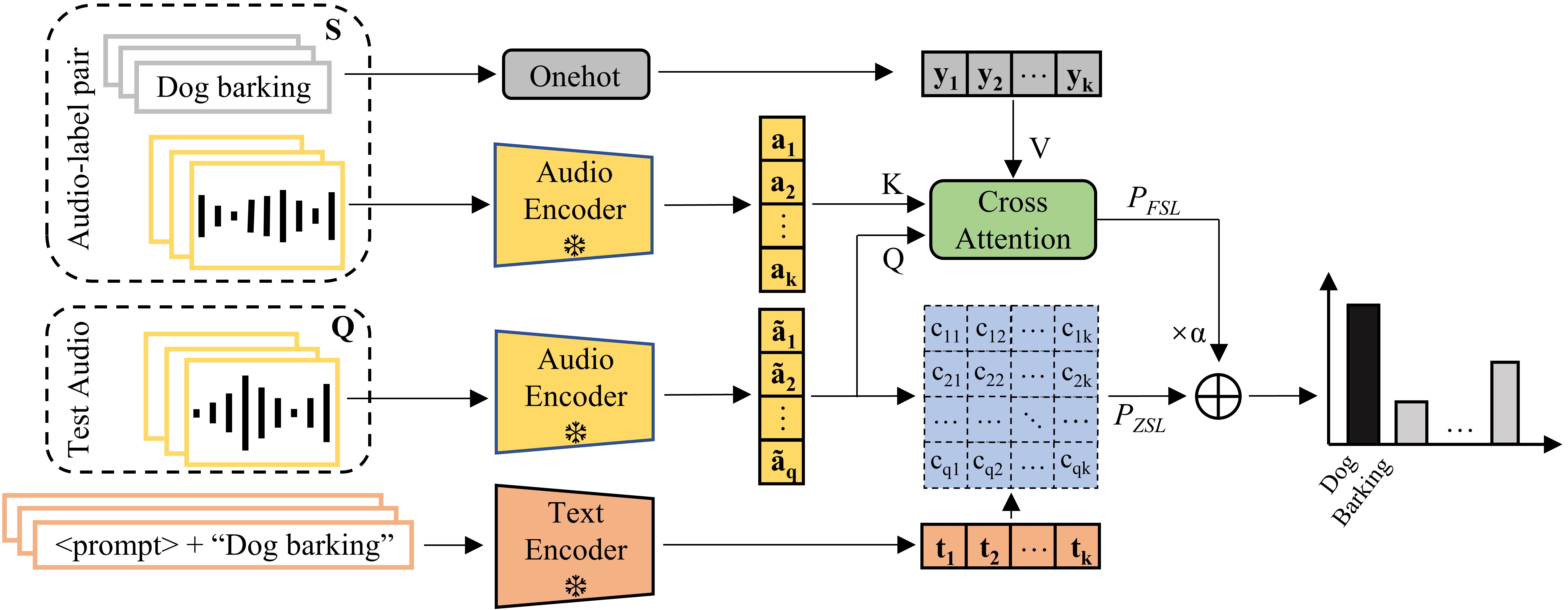 CLAP models made impressive progress in zero-shot knowledge transferring, but can we bootstrap them in few-shot scenarios while maintaining its capacity as a zero-shot classifier?
CLAP models made impressive progress in zero-shot knowledge transferring, but can we bootstrap them in few-shot scenarios while maintaining its capacity as a zero-shot classifier?
We presented the Treff adapter, a training-efficient adapter for CLAP, to boost zero-shot classification performance by making use of a small set of labelled data. Specifically, we designed CALM to retrieve the probability distribution of text-audio clips over classes using a set of audio-label pairs and combined it with CLAP’s zero-shot classification results. Furthermore, we designed a training-free version of the Treff adapter by using CALM as a cosine similarity measure. Experiments showed that the proposed Treff adapter is comparable and even better than fully-supervised methods and adaptation methods in low-shot and data-abundant scenarios. While the Treff adapter shows that combining large-scale pretraining and rapid learning of domain-specific knowledge is non-trivial for obtaining generic representations for few-shot learning, it is still limited to audio classification tasks. In the future, we will explore how to use audio-language models in diverse audio domains.
See more details in the paper If you find this paper is helpful, please cite this paper.
@misc{liang2023adapting,
title={Adapting Language-Audio Models as Few-Shot Audio Learners},
author={Jinhua Liang and Xubo Liu and Haohe Liu and Huy Phan and Emmanouil Benetos and Mark D. Plumbley and Wenwu Wang},
year={2023},
eprint={2305.17719},
archivePrefix={arXiv},
primaryClass={eess.AS}
}